조회수: 10296 / 추천: 86
구글(google.com)은 세계 최대 인터넷 검색사이트이다. 규모와 인기만큼이나 구글을 둘러싼 법적 분쟁도 많고 다양하다. 2004년 4월 작가이자 변호사인 블레이크 필드는 구글사를 상대로 저작권침해소송을 제기했다. 그는 구글이 '저장된 페이지(cached)'를 제공하여 인터넷 사용자로 하여금 저장된 페이지에서 자신의 저작물을 다운로드받을 수 있도록 하는 것은 자신의 저작권을 침해한 것이라고 주장했다. 올해 초 나온 미국 네바다주 지방법원의 결론은 원고의 청구 기각이다. 원고의 소송기술이 패소의 큰 원인이기는 했지만, 이 판결은 인터넷 상에서 저작물의 공정이용 사례를 보탰다는 점에서 흥미롭다.
이 법적 공방을 이해하기 위하여 일단 구글로 들어가 보자. 인터넷에서 접근할 수 있는 웹페이지 수는 수십 억 개가 넘는다고 한다. 검색 엔진이 이 모든 페이지의 위치를 파악하고 분류하는 일을 손으로 일일이 할 수는 없다. 그래서 구글도 다른 검색엔진들처럼 구글봇(googlebot)이라는 자동프로그램을 사용한다. 구글봇은 인터넷 전체를 끊임없이 헤집고 다니면서 쓸만한 웹페이지의 위치를 파악하고 분석해서 검색가능한 웹 인덱스를 만든다. 이 과정에서 구글은 찾아낸 각 웹페이지를 복제하여 캐쉬(cache)라는 임시 저장공간에 그 페이지들의 HTML 코드를 저장하는데, 캐쉬에 저장된 웹페이지 중 입력된 검색어와 일치하는 말을 포함하는 페이지가 검색결과로서 보여지게 되는 것이다.
실제로 구글에 들어가 '네트워커'를 검색해 보자. 다음과 같은 검색 화면이 뜬다.
 |
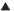 구글에서 '네트워커'를 검색한 화면 구글에서 '네트워커'를 검색한 화면 |
구글 검색결과를 보면 검색된 웹페이지의 제목이 가장 먼저 뜬다. 제목을 클릭하면 사용자는 그 페이지로 바로 이동할 수 있다. 제목 다음에는 작은 글씨로 검색된 웹페이지의 짧은 발췌문이 나온다. 그 다음 검색된 페이지의 전체 URL이 제공되며, 그것과 동일한 글씨크기로 '저장된 페이지(Cached)'라고 표시된 링크가 뜬다.
'저장된 페이지'를 클릭하면 사용자는 검색된 페이지의 본래 웹사이트로 접속하는 것이 아니라 구글 시스템의 캐쉬에 저장된 웹페이지의 사본을 볼 수 있다. 저장된 페이지는 구글봇이 가장 최근에 방문한 당시의 그 페이지의 스냅사진과 같다. 따라서 '저장된 페이지'는 웹페이지의 주인으로부터 명시적인 허락을 받지 않고 그 페이지를 복제하여 사용자에게 제공하므로, 만약 웹페이지가 저작물을 포함한다면(대부분은 그러할 것이다) 저작물을 저작권자의 허락 없이 복제하여 전송하는 결과가 된다. 그렇다면 '저장된 페이지'는 저작권 침해라고 해야 할까? 저작권법상의 문언을 형식적으로 파악하면 '저장된 페이지'를 저작권자 허락없이 제공하는 것은 저작권 침해로 인정될 여지가 매우 높다. 그러나 '저장된 페이지'는 본래 페이지에 접속할 수 없는 경우에도 종종 원하는 자료를 제공해 주므로 매우 유용하며, '저장된 페이지'가 제공된다고 해도 본래 저작권자가 웹사이트에 공개한 자료를 저장한 것이므로 저작권의 경제적 이익을 부당하게 침해하는 것도 아니다. 또한 만일 '저장된 페이지'를 합법적으로 제공하기 위해서 일일이 해당 웹사이트의 주인들에게 개별적으로 접촉하여 허락을 얻어야 한다면 그러한 서비스를 제공하는 것은 불가능하다. 인터넷의 광범위함이나 역동성은 그러한 시간적 여유를 허락하지 않기 때문이다. 따라서 '저장된 페이지' 제공을 쉽게 저작권 침해라고 단정해서는 안 된다.
네바다 지방법원은 저장된 페이지가 원고의 저작권을 침해한 것으로 인정할 수 없다고 하면서 다음과 같은 사정을 고려하였다. 우선 법원은 원고 필드가 "사용자들이 구글이 제공하는 '저장된 페이지'에 접속하여 그 내용을 다운로드받을 때 구글은 직접적으로 그의 저작권을 침해한 것이다"라고 주장하였을 뿐이고, "구글 스스로 그 시스템 내에 저장하였다가 사용자에게 제공하는 것 자체를 저작권 침해"라고 주장하지 않았다는 점에 주목했다. 저작권 직접침해가 있음을 입증하려면 원고는 우선 저작권이 자신에게 있다는 것과 피고에 의한 저작권 직접침해를 증명해야 한다. 피고의 저작권 직접침해란 의지적 행위를 말하는 것이며 다른 사람에 의하여 야기된 기계에 의한 자동 복제만으로는 충분하지 않다는 것이 법원의 입장이다. 구글 스스로 그 시스템 내에 어떤 웹사이트를 복제하여 저장하였다가 사용자에게 그 '저장된 페이지'를 제공하는 것은 분명 구글 스스로의 의지적 행위에 의한 것이므로 저작권 침해로 볼 수 있다. 그러나 사용자의 클릭행위가 완료되었을 때 구글의 저작권 침해가 성립한다고 보면 이 과정에서 구글은 수동적이며 구글의 컴퓨터는 사용자의 요구에 따라 자동적으로 반응하는 것에 지나지 않는다. 즉, 의지적 행위가 아니라 '다른 사람에 의하여 야기된 기계에 의한 자동 복제'에 불과하게 된다. 따라서 이 경우 원고의 주장에 의하여는 구글의 저작권 침해 자체가 인정되지 않는다고 보았다.
반면 법원은 구글측의 3가지 항변은 모두 받아들였다.
첫째, 저작권자는 메타태그를 통해 검색이나 저장을 거부할 수 있다는 점을 필드도 알고 있었으므로, 그가 그러한 메타태그를 사용하지 아니한 것은 구글의 복제, 전송 행위를 묵시적으로 허락한 것으로 볼 수 있다. 웹사이트의 주인들은 HTML 코드에 포함되는 메타태그(meta-tag)에 특별한 지시를 넣거나 robots.txt 파일을 사이트에 올려놓음으로써 검색엔진과 소통이 가능하다. 구글봇이 페이지를 방문하면 구글봇은 메타태그를 읽고 그 지시에 따르게 된다. 따라서 사이트 주인이 "메타태그를 넣으면 구글봇은 그 페이지를 분석하지 않으며 구글의 웹 인덱스나 검색결과에 그 페이지를 포함시키지 못한다."라는 메타태그를 쓰면 저장된 페이지를 제공하지 않는다. 또한 "User-agent: * Disallow: /"라는 내용의 robots.txt 파일을 올려놓아도 검색엔진에 의한 검색이 차단된다. 만약 이러한 매타태그나 robots.txt를 사용하지 않았다면 저작권자는 구글의 행위를 묵시적으로 허락한 것으로 볼 수 있을 것이다.
둘째, 원고 필드는 오랫동안 구글이 '저장된 페이지'를 제공하는 것을 알고도 이의를 제공하지 아니하였기 때문에 구글은 원고 필드가 앞으로도 이의를 제기하지 아니할 것으로 신뢰하여 행동하였는데, 이제 와서 저작권 침해를 주장하는 것은 금반언의 원칙에 반한다고 보았다.
셋째, 구글의 행위가 저작권자의 동의없이도 저작물을 이용할 수 있는 경우인 '공정이용(fair use)'에 포함된다고 보았다. 미국 저작권법은 저작물 이용의 목적과 성격 (교육목적인지 상업적 목적인지 등), 저작물의 성격, 전체 저작물 중 이용되는 부분의 양과 비중, 저작물의 잠재적 시장 가치에 미치는 영향 등을 고려하여 공정이용에 포함되는지를 판단하도록 하고 있는데, 구글 캐쉬는 원고의 본래 저작물과는 다른 목적에 사용되며, 구글이 상업사이트라는 이유만으로 공정이용이 부정되는 것은 아니고, 필드도 자신의 저작물을 인터넷에 공개해 두었으므로 자신의 저작물이 널리 퍼지는 것을 원했던 것이며, 저장된 페이지를 제공한다고 하여 필드의 저작물의 시장가치에 실질적 영향을 주는 것도 아니라고 보아, 구글의 저장된 페이지를 공정이용이라고 인정하였다.
요 며칠전 한국복제전송권센터가 서울대학교 도서관의 학위논문 온라인 서비스를 저작권 침해라는 이유로 소송을 제기하였다는 보도가 있었다. 이번 구글 사건이 더 의미있게 다가오는 이유는, 사적 권리의 주장 앞에 사회적 연대의식은 설 곳이 없는 우리 사회의 세태 때문일 것이다.














