조회수: 6679 / 추천: 87
만약 처음 보는 어떤 사람이 프로그래머인지 아닌지 알고 싶다면(이런 경우가 얼마나 될지는 모르겠습니다만) 한 가지 좋은 방법을 알려드리겠습니다. 일단 빈 종이에 원통을 하나 그립니다. 그리고 이 원통을 보고 가장 먼저 떠오르는 이미지가 무엇인지 물어보는 거죠. 물론 돌아오는 대답은 블럭부터 시작해서 필통, 드럼통, 커피캔, 물컵, 스탠드, 의자 등 매우 다양할 것임이 틀림없습니다. 하지만 만약 상대방이 프로그래머라면 100이면 99 "데이터베이스"라고 대답하지 않을까 합니다.;;; 데이터베이스를 상징하는 기호가 바로 이 원통이기도 하지만, 프로그래밍에 있어 데이터베이스는 어디에도 빠지지 않는 매우 중요한 존재이기 때문입니다.
데이터베이스(Database)는 말 그대로 데이터를 저장하고 분류하고 찾기 쉽게 만들어 놓은 것입니다. 데이터는 단지 많다고 해서 가치 있는 것이 아니라 분류/정리가 잘되어 있어야 진정 가치를 발할 수 있기 때문에, 데이터베이스는 그런 의미에서 매우 중요한 역할을 담당하는 경우가 많죠.
책이나 음반 등을 많이 가지고 계신 분들은 이 말에 100% 공감하시리라 생각합니다. 책을 몇 천권 소유하고 있지만 방 한 구석에 쌓아놓고 보관하는 A씨의 예를 들어봅시다. 일단 방문객에게 허접하다는 인상을 주는 건 차지하고서라도, 어떤 책이 필요해져서 찾으려고 할 때 엄청난 시간과 노력이 들기 마련입니다. 먼지를 뒤집어쓰면서 책을 찾아봤지만 결국 찾는데 실패하게 된다면, A씨가 소장하고 있는 몇 천권의 책들은 아무런 가치를 만들어 줄 수 없습니다. 반면 몇 백 권밖에 안되지만 책꽂이에 제목 순으로 배열된 B씨의 책들은 가치 있게 사용되는 경우가 더 많겠죠.
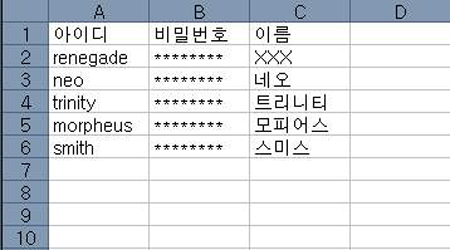
그래서인지 데이터베이스는 도서관과 유사한 점이 많습니다. 기본적으로 데이터베이스는 정보를 저장하고 보관하는 역할을 하는데, 도서관의 역할이 바로 그것이죠. 규모가 좀 되는 도서관에서는 방 별로 분류하여 책을 보관합니다. 소설, 인문서, 논문, 간행물, 외국서적 등 몇 가지 범주로 책을 분류하여 다른 방에 넣는데, 데이터베이스에서는 테이블(Table)이 이 역할을 합니다. 테이블은 보관하고자 하는 데이터의 가장 기본적인 집합으로서, 테이블을 정의하는 사람이 데이터의 종류에 맞게 열(컬럼, Column)을 지정해 주고 테이블을 생성하면 데이터를 저장할 준비는 완료됩니다. 예를 들어 회원 정보를 저장하기 위해 데이터베이스를 사용한다고 하면, 아이디/비밀번호/이름 등(주민등록번호 등은 받지 않아도 됩니다. ㅎㅎ)을 컬럼으로 잡고 테이블을 생성합니다. 그러면 테이블이라는 이름 그대로 하나의 표처럼 데이터를 저장할 구조체가 만들어지게 되죠.
테이블은 표와 같습니다. 아이디, 비밀번호 등을 구분한 열이 있다면, 하나의 완전한 데이터로 저장되는 renegade/********/XXX 를 행(로우, row)이라고 합니다. 새로운 데이터는 하나의 새로운 행이 되어 테이블에 추가됩니다. 그리고 만약 다른 종류의 데이터를 저장할 필요성이 생기면 새로운 테이블을 만들고 데이터를 넣으면 되는 것이죠.
테이블에는 저장한 순서대로 데이터가 쌓이게 됩니다. 이렇게 되면 저장할 때에는 별 문제가 없겠지만 특정한 데이터를 찾고자 할 때 불편함이 따르게 됩니다. 10만 행의 데이터가 들어있는 위의 회원 정보 테이블에서 oracle(!!!)이라는 아이디를 가진 회원의 정보를 찾는다고 가정합시다. 그런데 운 나쁘게도 oracle의 회원 정보는 99999번째로 저장되었습니다. 이런 경우에는 아이디가 oracle인지 확인하는 작업을 1번부터 시작해서 99999번 반복해야 합니다. 참 불편하기 짝이 없는 시추에이션인 것이죠.
보통 도서관에서 책을 찾을 때 이러한 불편을 덜기 위해 색인을 사용합니다. 색인은 가나다 순으로 분류되어 있고 특정 책에는 코드값이 있어서 이 코드값을 통해 쉽게 책의 위치를 알아낼 수 있습니다. 데이터베이스에도 역시 색인(인덱스, Index)이 있습니다. 테이블의 특정 컬럼에 인덱스를 걸어주면 쉽게 데이터가 있는 행의 위치를 파악할 수 있죠. 회원 정보 테이블의 아이디 컬럼에 인덱스를 걸어준다면, 테이블에 데이터가 저장될 때마다 아이디와 데이터가 들어있는 행의 위치를 인덱스에 별도로 기록합니다. 그래서 나중에 oracle이라는 아이디를 통해 데이터를 검색하고자 할 때, 99999번째 위치라는 사실을 손쉽게 찾을 수 있는 것이죠.
이외에도 데이터베이스에는 데이터를 저장하고 찾기 쉽게 하기 위한 기능들이 많이 있습니다. 같은 아이디를 중복해서 저장하고 싶지 않다면 아이디 컬럼에 대해 유일성 제약조건(Unique Constraint)을 걸어주면 됩니다. 데이터가 하나 들어갈 때마다 1, 2, 3, 4 같이 자동으로 하나씩 늘어나는 번호를 데이터에 붙여주고 싶다면 일련번호 발생기(Sequence Generator)를 사용하면 되지요. 다른 테이블에서 회원정보 테이블의 아이디 값을 반드시 참조하게 하고 싶다면 아이디 컬럼을 외부키(Foreign Key)로 잡아주면 됩니다.
이렇게 데이터를 테이블로 저장하고, 인덱스를 걸어주고, 다른 테이블의 값을 참조하게 하게 하면 각 테이블은 서로간의 관계를 맺게 됩니다. 이런 관계를 도면화시킨 것을 개체관계도(ERD, Entity Relationship Diagram)이라 부르며, 이는 시스템의 구조를 설명해 주는 중요한 문서 중 하나로 작성됩니다.
앞에서 프로그래머를 분간하는 방법을 말씀 드렸는데요, 그 방법을 사용할 때 주의할 점이 하나 있습니다. 데이터베이스는 프로그래밍에서 빼놓을 수 없는 중요한 부분이기는 하지만, 저를 포함한 많은 프로그래머들은 데이터베이스를 다루는 것을 별로 좋아하지 않습니다. 순수하게 데이터만을 만지작거리는 건 아무래도 지루하고 재미없는 일이기 때문이죠. 원통을 그려 보였을 때 상대방이 프로그래머라면 알러지 반응을 보일 수도 있으니 주의하세요. :)